
It is that time of year again: Truckloads of lights are dumped into store windows, people scramble to get their Christmas shopping done, and it is becoming increasingly unbearable to listen to the radio. Of course, the most important element of the season is still ahead of us – all across the Commonwealth people are eagerly awating the Queen's Christmas Broadcast. Well... let's assume they do for the purposes of this blog post. We figured that in order to shorten the wait, it might be fun to take a look back at the history of the speeches her Majesty has given over the years.
Ever since 1952, the Queen has kept with the tradition of addressing her people as the year draws to a close. Let's begin by checking out the transcripts of her speeches. You can find them at http://www.royal.gov.uk/ImagesandBroadcasts/TheQueensChristmasBroadcasts/ChristmasBroadcasts/ChristmasBroadcast1952.aspx.
Collecting the data
Our aim is to scrape the first 50 Christmas Broadcasts the Queen has given – years 1952 to 2001 – and to play around with them a little in the second part of this post. For the scraping part of the exercise we rely on the Selenium framework and on the Rwebdriver package which provides an easy-to-use wrapper. The Selenium framework allows us to interact with a web browser from within R and to perform the scraping task almost as though we were doing it manually.
If you haven't already done so, start by downloading the Rwebdriver package from Github using the functionality that is provided in the devtools package.
devtools::install_github(rep = "crubba/Rwebdriver")
library(Rwebdriver)
Be sure to also have the Selenium server file on your machine. You can get it here. While we're at it, we also load the other packages that we need for the scraping excercise and the tiny analysis.
library(XML)
library(stringr)
library(wordcloud)
Needless to say that we also need some awesome colors that we get from the wesanderson package...
library(wesanderson)
la_col <- wes.palette(name = "Zissou", n=5, type = F)
la_cont <- wes.palette(name = "Zissou", type = "continuous")
We begin by opening up a system prompt and initiate the server by running the file that we previously downloaded.
java -jar selenium-server-standalone-2.44.0.jar
Alterantively, we can invoke the selenium server from within R by using the system() command with the option wait set to FALSE.
system("java -jar path/to/selenium-server-standalone-2.44.0.jar", wait=F)
By the way, if all of this seems completely strange to you – the technical aspects, mind you, not the Queen! – you might want to check out chapter 9 in our book for more information. After this step, we open a window in the Firefox browser.
start_session(root = "http://localhost:4444/wd/hub/", browser = "firefox")
The idea is simply to iterate over the URL printed above and to replace the years in each iteration. The resulting URLs are posted using the post.url() function and the source code is collected via page_source(). We parse the source code with functionality from the XML package (htmlParse()) and select the content of the speech with an XPath expression that looks for a content id in a div node. Specifically, we retain the value of the node via xmlValue, resulting in a character vector, where each entry corresponds to one paragraph in the speech. As the first paragraph is not part of the speech, but provides some background information on the historical circumstances of the speech, we discard it. In accordance with our rules of good scraping practice, we want to generate as little web traffic as possible. Therefore, we write the speeches to a folder Queens_Speeches so we don't have to perform the web scraping over and over if we have to go back to the exercise.
dir.create("Queens_Speeches", showWarnings = F)
for(i in 1952:2001){
post.url(str_c("http://www.royal.gov.uk/ImagesandBroadcasts/TheQueensChristmasBroadcasts/ChristmasBroadcasts/ChristmasBroadcast", i, ".aspx"))
page.source <- page_source()
parsed.html <- htmlParse(page.source)
speech <- xpathSApply(parsed.html, '//div[@id="content"]/p', xmlValue)
speech_shortened <- speech[2:length(speech)]
write(speech_shortened, str_c("Queens_Speeches/", i, ".txt"))
}
Finally, we quit the session and terminate the server.
quit_session()
A brief look at the data
To perform some simple analyses, we have to load the data back into R. To do so, we set up an empty list() to hold the speech data. Next, we iterate over the years and add them to the list using the readlines() function from base R. Purely for convenience, we collapse the paragraphs into one text as we do not make use of the structure of the texts. This is done using the str_c() function from the stringr package.
speeches <- list()
for(i in 1952:2001){
speeches[[as.character(i)]] <-
str_c(
readLines(
str_c("Queens_Speeches/", i, ".txt")),
collapse = "\n")
}
First, we investigate the length of the Queen's speeches. We generate two vectors, queens.characters and queens.words, one containing the number of characters in each speech, the other containing the number of words. Both are filled by relying on the sapply() function to avoid unnecessary for-loops. The number of characters are counted using the nchar() function, while the words are counted as the number of word characters (\\w) using the str_count() function from the stringr package. Not surprisingly, the figure shows that we can safely assume that the number of characters are a very good approximation of the speech length.
queens.characters <- sapply(speeches, nchar)
queens.words <- sapply(speeches, str_count, "\\w+")
plot(
queens.characters,
queens.words,
xlab = "Number of characters in speech",
ylab = "Number of words in speech",
bty = "n", col = la_cont(length(speeches)), pch = 19
)
litems <- round(quantile(as.numeric(names(speeches)), seq(0, 1, 0.1)) )
legend("bottomright",
legend = names(speeches)[match(litems,names(speeches))],
col = la_cont(length(speeches[litems])),
cex = 0.8,
pch = 19)
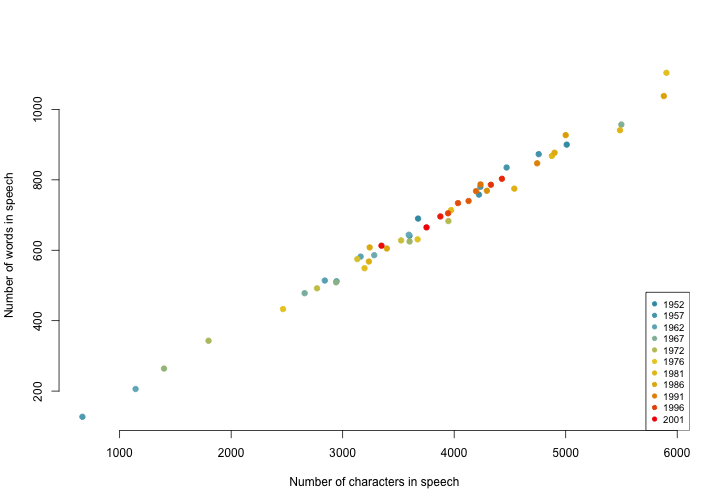
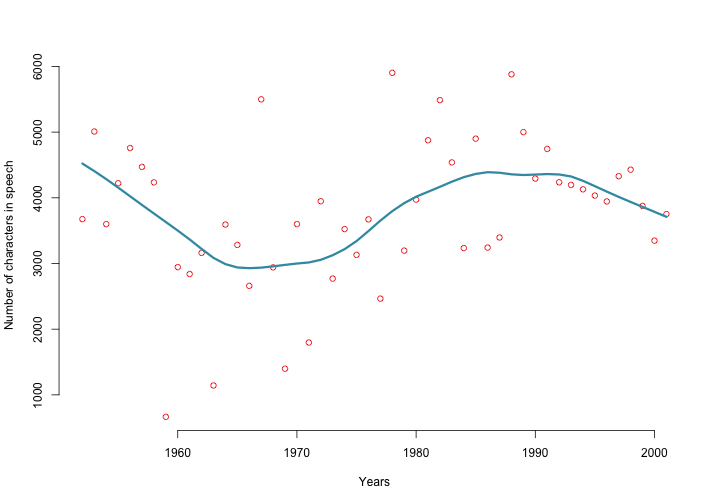
Let's check out the length of the speeches the Queen has given over the years. The second figure displays the number of characters in the speeches by year. We add a smoothing line to better make out trends in the data. We find that in the 1960s and early 1970s the Queen wanted to make sure to be home in time for supper, keeping it short and sweet. Conversely, she had a lot more to say in the 1980s and early 1990s. More recently, we observe a slight downward trend again – let's see whether this trend continues this year.
plot(
names(speeches),
queens.characters,
xlab = "Years",
ylab = "Number of characters in speech",
bty = "n",
col = la_col[5]
)
lines(
names(speeches),
lowess(queens.characters, f = 1/3)$y,
lwd = 3, col = la_col[1]
)
One simple way for assessing the content of textual data are the popular word clouds. We generate two word clouds, one for the first 25 years of material (1952-1976), one for the years 1977-2001. Given the changing political landscapes, the figures are actually remarkably similar. Some interesting observations can be made, nonetheless. For example, the Queen has had a lot more to say about children in recent years, while the importance of the commonwealth has decreased in her speeches.
set.seed(5)
wordcloud(unlist(speeches[1:25]), min.freq = 15, colors=la_cont(10))
legend("bottomleft", "1952 - 1976", cex = 1 , bty = "n", border = "white", fill = "white")
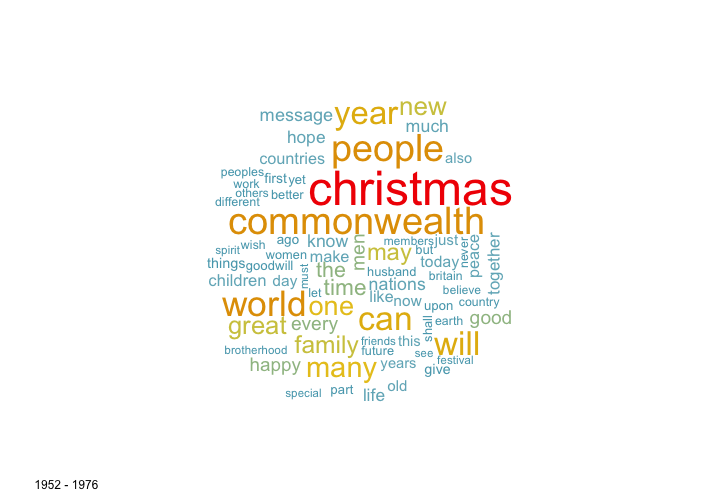
wordcloud(unlist(speeches[26:50]), min.freq = 15, colors = la_cont(10))
legend("bottomleft", "1977 - 2001", cex = 1 , bty = "n")
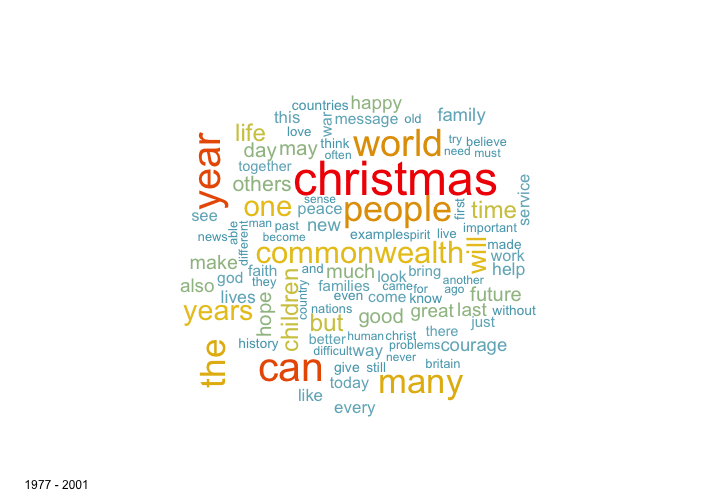
As always, there are probably more interesting aspects hidden in the data. We encourage you to trace the steps in this blog post, to collect the data yourself and to play around with it.
Have a Merry Christmas and a Happy New Year!