
About a month ago, I announced the release of the htmltable package. In the meantime a lot has happened. Years have changed and the –presumably formidable– htmlTable package has been released on CRAN. So much for my beloved package name. Since I need a new one, let's find something shorter, more googleable ... how about ... htmltab? htmltab it is.
What the htmltab package is about
The main goal behind htmltab is to make the process of getting structured information out of HTML tables as simple and quick as possible. You can read more about the motivation and see some examples of how to use it in an earlier blog post. Essentially, htmltab allows you to take HTML tables that exhibit different kinds and levels of untidiness (such as cell-spanning, non-data junk like footnotes and superscripts, etc.) like in this one:
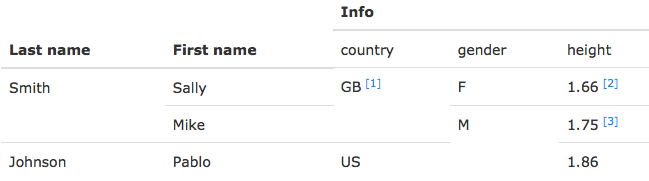
... and turn them into R data frames that are readily useful for further analysis:
install.packages("htmltab")
library("htmltab")
url <- "http://www.r-datacollection.com/blog/tab.html"
htmltab(doc = url)
## Warning: Argument 'which' left unspecified. Choosing first table.
## Last name First name Info >> country Info >> gender Info >> height
## 1 Smith Sally GB F 1.66
## 2 Smith Mike GB M 1.75
## 3 Johnson Pablo US M 1.86
New release: v. 0.5.0
The newest iteration of this package has just been published on CRAN, but you can also download the developer version from the GitHub repo. This release was mostly concerned with bug fixing, but additionally a few significant, presumably code-breaking changes to the previous version have been made. I won't go into much detail of these changes here, but you can read it up in the change log. Instead, I want to use this blog post to demonstrate the usage of the package's function and highlight some of the design decisions.
When and how to use header and body arguments
Ideally, every HTML table on the Web would ultilize the correct semantic mark-up to signify header and body elements (by using thead/tbody). Since this is not the case and web developers are free to build tables even without these tags, htmltab uses a couple of heuristics to identify both elements and assemble the R table correctly. If you come across a table you want to scrape, I suggest to proceed as follows: First, try htmltab() without specifying the header or body arguments, and observe if the returned data frame is assembled correctly. If this is not so, try to pass an information (numeric or XPath) for the header rows to the header argument. If there are still problems with the body of the table, invest a little bit of time to create an XPath expression for the respective body rows. I illustrate this process with an example.
Demonstrating the process with a tough table
The Australian Bureau of Statistics publishes on their site drug-related death statistics. Let's try to get information from table 1 into R. At a minimum, htmltab() needs to be fed the HTML document as well as an information where to find the table in the page. After a bit of testing out (XPath would have been more elegant), I found that it is the ninth table in the page, so I pass 9 to the which argument:
url <- "http://www.abs.gov.au/ausstats/abs@.nsf/cat/3321.0.55.001"
htmltab(doc = url, which = 9)
## Warning: Neither <thead> nor <th> information found. Taking first table
## row. If incorrect, specifiy header argument.
## Warning: No header generated. Try passing information to header or
## colNames.
## V1 V2
## 1 <NA> <NA>
## 2 <NA> EXAMPLE/COMMON NAME
## 3 <NA> EXAMPLE/COMMON NAME
## 4 T39.1 4-Aminophenol derivatives EXAMPLE/COMMON NAME
## 5 T40.0-40.2 Opium, heroin & other opioids Heroin, morphine
## 6 T40.3 Methadone Methadone
## 7 T40.4-40.9 Other narcotics & hallucinogens Pethadine, cocaine, cannabis
## 8 T42.4 Benzodiazepines Valium
## 9 T43.0-43.2 Antidepressants Prozac
## 10 T43.3-43.5 Antipsychotics and neuroleptics Promazine
## 11 T43.6 Psychostimulants Amphetamines
## 12 T51 Alcohol (c) Alcohol
## 13 Long term organ damage (d) <NA>
## 14 <NA> <NA>
## 15 Total number of deaths <NA>
## V3 V4 V5 V6 V7 V8 V9
## 1 <NA> ACCIDENTAL ACCIDENTAL <NA> SUICIDE SUICIDE <NA>
## 2 <NA> MALES FEMALES <NA> MALES FEMALES <NA>
## 3 <NA> % % <NA> % % <NA>
## 4 Paracetemol <NA> 3 10 <NA> 9 13
## 5 <NA> 39 29 <NA> 22 17 <NA>
## 6 <NA> 15 10 <NA> 6 1 <NA>
## 7 <NA> 20 14 <NA> 10 5 <NA>
## 8 <NA> 21 28 <NA> 31 25 <NA>
## 9 <NA> 11 23 <NA> 28 28 <NA>
## 10 <NA> 1 5 <NA> 4 7 <NA>
## 11 <NA> 8 7 <NA> 2 1 <NA>
## 12 <NA> 18 18 <NA> 14 11 <NA>
## 13 <NA> 3 2 <NA> 1 0 <NA>
## 14 <NA> no. no. <NA> no. no. <NA>
## 15 <NA> 480 230 <NA> 151 134 <NA>
The result is dismal. The header is completly off target and has been pushed into the body. When this happens, it is best to take a look at the table's HTML code to deduce what's going on (e.g. using Firefox Developer Tools or Firebug). From looking at the code I learnt that every horizontal break line takes a single table row. This is a massive problem because htmltab() assumes table content to be data and not stylistic frippery. In order to correctly assemble the table, I pass direct information to the header and body argument. Header information appear in the second, fourth and sixth row and for the body, I create an XPath that uses every row after the sixth and discards every row that uses horizontal lines:
htmltab(doc = url, which = 9, header = c(2,4,6), body = "//tr[position() > 6 and not(./td[hr])]")
## V1 EXAMPLE/COMMON NAME
## 1 T39.1 4-Aminophenol derivatives Paracetemol
## 2 T40.0-40.2 Opium, heroin & other opioids Heroin, morphine
## 3 T40.3 Methadone Methadone
## 4 T40.4-40.9 Other narcotics & hallucinogens Pethadine, cocaine, cannabis
## 5 T42.4 Benzodiazepines Valium
## 6 T43.0-43.2 Antidepressants Prozac
## 7 T43.3-43.5 Antipsychotics and neuroleptics Promazine
## 8 T43.6 Psychostimulants Amphetamines
## 9 T51 Alcohol (c) Alcohol
## 10 Long term organ damage (d) <NA>
## 11 <NA> <NA>
## 12 Total number of deaths <NA>
## ACCIDENTAL >> MALES >> % ACCIDENTAL >> FEMALES >> %
## 1 3 10
## 2 39 29
## 3 15 10
## 4 20 14
## 5 21 28
## 6 11 23
## 7 1 5
## 8 8 7
## 9 18 18
## 10 3 2
## 11 no. no.
## 12 480 230
## SUICIDE >> MALES >> % SUICIDE >> FEMALES >> %
## 1 9 13
## 2 22 17
## 3 6 1
## 4 10 5
## 5 31 25
## 6 28 28
## 7 4 7
## 8 2 1
## 9 14 11
## 10 1 0
## 11 no. no.
## 12 151 134
That did the job! The table looks fine and orderly, the header has been recast into an easy to parse format, empty cells have been replaced by NA and surplus non-data columns have been automatically deleted from the table.
Hierarchy of semantic table elements
htmltab uses the following heuristics for header and body identification:
- If you pass an XPath statement to header or body, htmltab returns these elements for you.
- Likewise, if you pass a numeric vector to one or both of the arguments, htmltab returns the table rows that correspond to the numeric values (negative indexes are currently not allowed).
- If you pass no information to the header / body argument:
- For the header: htmltab checks whether there is a thead node present, and if yes, takes the rows in thead as the header. If there is no thead, htmltab checks if there are rows with all th elements, and if so, takes the corresponding rows. If this test also fails, htmltab takes the first row and prints a warning.
- For the body: htmltab checks whether there is a tbody node present, and if yes, takes the rows in tbody as the body. If there is no tbody, htmltab asserts if there are td elements present, and if so takes the corresponding rows.
htmltab() works on the assumption that there actually is header information somewhere in the table. The function defaults to taking the first table row as the header if no other structural information is available. If this behaviour is wrong, then you need to specifically tell htmltab() to omit this part of the process by setting header = 0.
Complementarity of header and body elements
Additionally, htmltab now also tries to captialize on the fact that header and body are mutually exclusive elements of an HTML table, so you oftentimes only have to specify one argument. For example, if you pass a numeric information to header (e.g. header = 1:2), but leave body unspecified, htmltab selects the most appropriate body rows but certainly not the first two in the table.
Report issues
If you experience problems with htmltab, I would like to hear about it to improve the project. Please use my github repo to report the issue.