
The following is a guest post by Jana Blahak and Jan Dix (University of Konstanz), with support from Simon Munzert.
We are happy to introduce our freshly created rzeit package. It connects to the Content API at ZEIT Online, a German newspaper website. In short, the package allows you to
- conduct an unfiltered search for articles,
- use a variety of parameters to refine query fields, e.g. to specify content and time, and
- easily inspect meta as well as article data.
The package is made publicly available at GitHub. In this blog post, we demonstrate basic features of the package. In a follow-up post, we will dig deeper into the matter and show how the package can be used to construct networks of popular German politicians.
Setup
Currently, the package is only available on GitHub. Using the devtools package, you can easily install it:
devtools::install_github("tollpatsch/rzeit")
library(rzeit)
In the following example, we also draw on additional, well-known packages:
library(rzeit)
library(stringr)
library(jsonlite)
library(lubridate)
Basic functions
To be able to work with the API, we have to fetch an API key first. There is no sophisticated authentication process involved here--just go to the developer page and sign up by providing your name and a valid email address.
With zeitSetApiKey, we provide a comfortable function that stores the key in the R environment You only have to do this once; the next time R is launched this key is automatically available and fetched by the package's functions:
zeitSetApiKey(apiKey = "set_your_api_key_here")
Next, we can start tapping the API. fromZeit represents the core function of the package. Again, because the API Key is stored in the environment, we do not have to pass the key explicitly (but still could do so using the api argument). As an example, we collect articles that include "Angela Merkel" in the article body, headline or byline:
results <- fromZeit(q = "Angela Merkel",
limit = "100",
dateBegin = "2015-06-01",
dateEnd = "2015-08-01")
Note that for the ease of exposition, we limited the number of collected results to 100 here using the limit argument. The maximum limit per call is 1000. Further, we restricted the search to articles that were published in a time period of about four months.
The results object is of class list and provides information about the articles found as well as the number of hits for a given period. To extract information about the latter, we can draw on the zeitFrequencies function, which takes the results object as main argument and returns a data frame that includes a continous list of dates in choosen sequences and the related frequencies:
freq <- zeitFrequencies(ls = results,
sort = "days",
save = FALSE)
head(freq)
## date dayCount freq freqPro
## 1 2015-07-06 1 3 30
## 2 2015-07-07 2 4 40
## 3 2015-07-08 3 9 90
## 4 2015-07-09 4 4 40
## 5 2015-07-10 5 1 10
## 6 2015-07-11 6 1 10
Apart from these meta data, we can also process substantive article information. The function zeitToDf converts the list returned from fromZeit into a data frame:
articles <- zeitToDf(ls = results,
sort = "days",
save = FALSE)
names(articles)
## [1] "daynum" "date" "title" "subtitle" "snippet"
## [6] "teaserText" "teaserTitle" "link"
Finally, we offer the function zeitPlot that offers a first inspection of the collected time series. It plots date versus frequencies based on the frequency data frame returned by zeitFrequencies:
zeitPlot(df = freq)
Example
So much for the package's basic functionality. In the following, we marginally modify our running example to demonstrate additional features of the fromZeit function.
Perform queries
Again, we are looking for articles on Angela Merkel. However, we now set the fromZeit argument multipleTokens = TRUE. The effect of this is that the API will return results both for "Angela" and "Merkel". There are more than 1000 hits in the given time span (covering all of 2013 and 2014), but given the limit of 1000, the function only returns the first thousand articles in descending order:
results_split <- fromZeit(q = "Angela Merkel",
limit = "1000",
dateBegin = "2013-01-01",
dateEnd = "2014-12-31",
multipleTokens = TRUE)
results_split <- zeitFrequencies(ls = results_split,
sort = "month",
save = FALSE)
frequencies_split <- results_split
For the second run, we set multipleTokens = FALSE. The API will return results for the entire string "Angela Merkel". Furthermore, we set limit = "1000" and split = FALSE. The default value for the split argument is TRUE, which allows us to circumvent the technical limit of 1000 articles per query for the whole time span, as the search is now split into monthly searches. It is unlikely that there are more than 1000 articles on Angela Merkel per month, so we expect to capture all relevant articles in the given time period. If we set split = FALSE, however, only the most recent 1000 hits (as defined with the limit argument) are returned:
results_withoutsplit <- fromZeit(q = "Angela Merkel",
split = FALSE,
limit = "1000",
dateBegin = "2013-01-01",
dateEnd = "2014-12-31",
multipleTokens = FALSE)
results_withoutsplit <- zeitFrequencies(ls = results_withoutsplit,
sort = "month",
save = FALSE)
frequencies_withoutsplit <- results_withoutsplit
Plot results
Lastly, we plot the results of the examples next to each other:
par(mfrow=c(1, 2))
zeitPlot(frequencies_withoutsplit, title = "without split", absolute = FALSE)
zeitPlot(frequencies_split, title = "with split", absolute = FALSE)
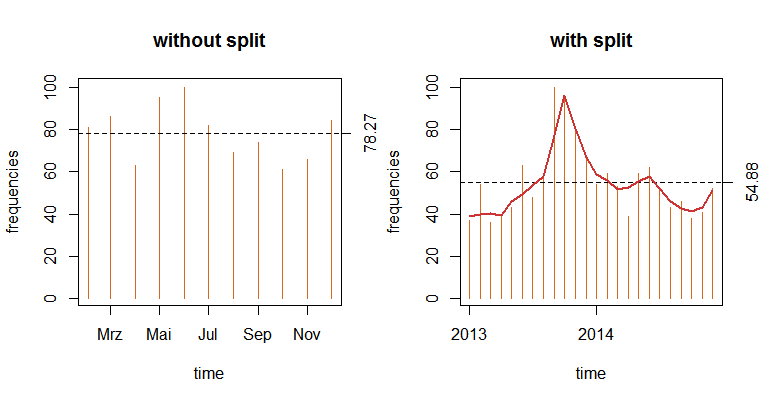
We see that using the second call with split = FALSE, we gathered data between February and December 2014, although we originally specified a longer time span. This is due to the limit of 1000 returned hits per call. This can still be of use, however, if you are primarily interested in a limited number of hits that do not necessarily have to cover the enire time span. Using the first call, we retrieved data for the entire time period. Now we see a peak in attention of articles published on ZEIT Online in the second half of 2013--just about when Mrs. Merkel was running for here third chancellorship at the federal election that took place on September 22, 2013.
We hope that this little introduction to the rzeit package inspired you to start your own analyses. The package is still under very active development on GitHub. As always, we are looking forward to hear about your experience with the package Stay tuned for another application of the package on our blog! Next, we will construct network data out of newspaper articles.